国际计算机视觉与模式识别会议(CVPR 2025)即将于2025年6月11日至15日在美国田纳西州纳什维尔召开,该会议是由电气电子工程师学会(IEEE)举办的计算机视觉和模式识别领域的顶级会议,属于中国计算机学会(CCF)推荐的A类国际学术会议,在Google Scholar指标榜单中位列全球学术出版物第二,仅次于Nature。本年度召开的CVPR 2025共收到13008篇有效投稿,其中2878篇被接收,录取率为22.1%。在近期公布的CVPR 2025的录取结果中,北京大学视频与视觉技术国家工程研究中心仉尚航研究组师生有多项最新研究成果入选,相关简要介绍如下:
1. MoVE-KD: Knowledge Distillation for VLMs with Mixture of Visual Encoders
作者:Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning MA, Shanghang Zhang*
论文链接:https://arxiv.org/abs/2501.01709
摘要:视觉编码器是视觉-语言模型(VLMs)的基本组件,每个编码器都因其预训练的视觉基础模型不同而展现出独特的优势。为了充分利用这些编码器的能力,最近的研究在单一的VLM中引入了多个编码器,这导致了计算成本的显著增加。在本文中,我们提出了混合视觉编码器知识蒸馏(MoVE-KD),这是一种新颖的框架,可以将多个视觉编码器的独特能力蒸馏到一个高效且单一的编码器模型中。具体来说,为了减少冲突并保留每个教师编码器的独特性,我们采用了低秩适应(LoRA)和专家混合(MoEs)的方法,根据输入特征有选择地激活专门的知识,从而提高适应性和效率。为了规范知识蒸馏(KD)过程并提升性能,我们提出了一种基于注意力机制的知识蒸馏策略,该策略自适应地权衡不同的视觉编码器,并强调有价值的视觉标记,减轻了从多个教师复制全面但独特特征的负担。在诸如LLaVA和LLaVA-NeXT等流行的VLM上的广泛实验验证了我们方法的有效性。代码将会公开发布。
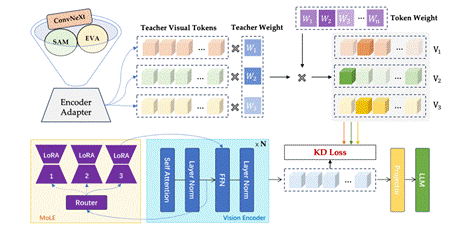
图1 The pipeline of MoVE-KD. MoVE-KD projects teacher encoders’ outputs using encoder adapters, assigns teacher weight andtoken weight based on CLlP's [CLs] attention. To mitigate knowledge conficts. we incorporates MoLE structure in the student encoder.
2. Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation
作者:Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilue Wang, Longzan Luo, Lily Lee, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, Shanghang Zhang*
论文链接:https://arxiv.org/abs/2411.18623
摘要:3D几何信息对于机器人操纵任务至关重要,因为机器人需要感知三维环境,推理空间关系,并与复杂的几何物体进行交互。近年来,研究逐渐聚焦于显式提取3D特征,但仍面临诸如:缺乏大规模机器人3D数据和潜在的空间几何信息丢失等挑战。为了解决这些问题,我们提出了Lift3D框架,通过隐式和显式的3D机器人表示逐步增强2D大规模预训练模型的3D空间感知能力,从而构建一个鲁棒的3D操纵策略。具体来说,我们首先设计了一个任务感知的掩码自编码器,该自编码器通过Mask与任务相关的Affordance token并重建深度几何信息,增强了2D基础模型的隐式3D机器人表达能力。在自监督微调之后,我们引入了一种2D基础模型Lifting策略,该策略在输入3D和2D模型的位置编码之间建立了位置映射关系。基于该映射,Lift3D利用2D基础模型直接显式的编码点云数据,借助大规模预训练知识提升3D模仿学习效率,同时最小化空间信息丢失。
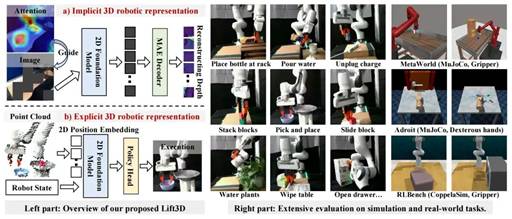
图2 Lift3D empowers 2D foundation models with 3D manipulation capabilities by refining implicit 3D robotic representations through task-related affordance masking and depth reconstruction, while enhancing explicit 3D robotic representations by leveraging the pretrained 2D positional embeddings to encode point cloud. Lift3D achieves robustness and surprising effectiveness in diverse simulation and real-world tasks.
3. RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
作者:Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, Xinda Xue, Qinghang Su, Huaihai Lyu, Xiaolong Zheng, Jiaming Liu, Zhongyuan Wang, Shanghang Zhang*
论文链接:https://arxiv.org/abs/2502.21257
摘要:近年来,多模态大型语言模型(Multimodal Large Language Models, MLLMs)在多种多模态应用场景中展现出卓越的性能。然而,这些模型在机器人领域的应用,尤其是在长视野操作任务中,仍存在显著不足。这些不足主要源于当前MLLMs缺乏三项关键的机器人大脑功能:任务规划能力,即将复杂任务指令分解为可执行的子任务;可供性感知能力,即识别和感知交互对象的可操作区域;以及轨迹预测能力,即根据任务指令预测从起点到目标位置的完整路径。为了提升机器人大脑从抽象到具体的核心能力,我们提出了ShareRobot,这是一个高质量的异构数据集,能够标注多维信息,包括长程任务规划、对象交互区域和末端执行器轨迹。基于此数据集,我们开发了RoboBrain,这是一种基于MLLM的模型,融合了机器人和通用多模态数据,采用多阶段训练策略,并充分利用长视频和高分辨率图像的优势,以增强其机器人操作能力。大量实验表明,RoboBrain在多种机器人任务中实现了最先进的性能,展示了其在提升机器人大脑能力方面的巨大潜力。
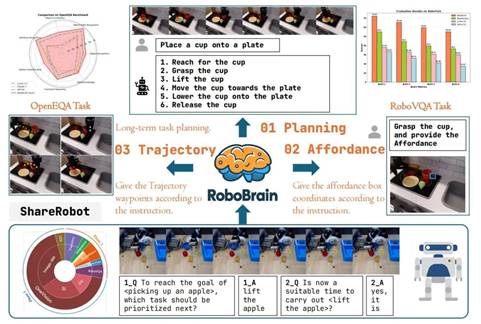
图3 Overview of RoboBrain. RoboBrain consists of three key robotic capabilities: planning capability, affordance perception, and trajectory prediction. RoboBrain outperforms previous MLLMs in robotics tasks. The bottom part shows the composition of RoboBrain’s training data and provides a specific example of visual question answering from our proposed ShareRobot. Best viewed on screen.
4. Decouple Distortion from Perception: Region Adaptive Diffusion for Extreme-low BitratePerception Image compression
作者:Jinchang Xu, Shaokang Wang, Jintao Chen, Zhe Li, Peidong jia, Fei Zhao, Guoqing Xiang, Zhijian Hao, Shanghang Zhang*, Xiaodong Xie
摘要:利用扩散模型的生成能力,生成式图像压缩即使在极低比特率下也能实现令人印象深刻的感知保真度。然而,当前的方法往往忽略了图像的非均匀复杂性,限制了它们平衡全局感知质量和局部纹理一致性以及有效分配编码资源的能力。为了解决这个问题,我们推出了地图引导掩蔽真实图像扩散编解码器(MRIDC),旨在优化极低比特率压缩中局部失真和全局感知质量之间的权衡。MRIDC将矢量量化图像编码器与基于扩散的解码器集成在一起。在编码方面,我们提出了一个地图引导潜在掩蔽(MLM)模块,该模块根据先验信息有选择地掩蔽潜在空间中的元素,从而实现与图像复杂性一致的自适应资源分配。在解码方面,使用双向预测可控生成(BPCG)模块完成掩蔽的潜在,该模块引导扩散模型中的受限生成过程以重建图像。实验结果表明,MRIDC在极低码率下实现了最佳的感知压缩质量,有效保持了关键区域的特征一致性,提升了码率-失真-感知性能曲线,在平衡压缩效率和视觉保真度方面树立了新的标杆。

图4 Visual comparison of decoded images. (a) Original images with the user-specified RoI area highlighted by a green dashed box. (b) VAE compression method cannot achieve extreme-low bitrate considering distortion optimization, (c) PerCo sacrifices the consistencyof key areas to obtain realism at extreme-low bitrate, (d) Traditional encoders have severe blocking elfects at extreme-low bitrate. (e) The proposed method maintains the overall advanced perceptual quality and maintains the consistency of key areas.
5.Segment Any Motion in Videos
作者:Nan Huang, Wenzhao Zheng, Chenfeng Xu, Kurt Keutzer, Shanghang Zhang, Angjoo Kanazawa, Qianqian Wang
摘要:运动物体分割是实现视觉场景高层理解的关键任务,在众多下游应用中具有重要价值。人类能够轻松识别视频中的运动物体,但现有方法主要依赖光流提供运动线索,在非整体运动、复杂形变、运动模糊和背景干扰等挑战下常产生不完美的预测结果。我们提出了一种新颖的运动物体分割方法,通过融合长程轨迹运动线索与基于DINO的语义特征,并采用迭代式提示策略驱动SAM2模型实现像素级掩码密集化。该模型设计了时空轨迹注意力机制和运动-语义解耦嵌入,在优先关注运动线索的同时融入语义支持。跨多个数据集的广泛测试表明,我们的方法在复杂场景和细粒度多目标分割中均达到了领先水平,展现出卓越的泛化能力。
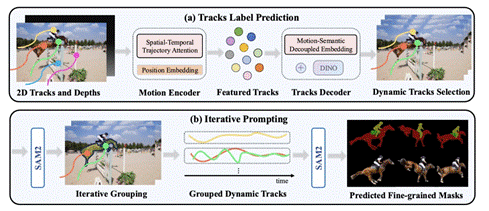
图5 Overview of Our Pipeline. We take 2D tracks and depth maps generated by off-the-shelf models [15, 63] as input, which are then processed by a motion encoder to capture motion patterns, producing featured tracks. Next, we use tracks decoder that integrates DINO feature [43] to decode the featured tracks by decoupling motion and semantic information and ultimately obtain the dynamic traiectories(a) Finally, using SAM2 [49], we group dynamic tracks belonging to the same object and generate fine-grained moving object masks(b).
6. Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
作者:Xiaoqi Li, Lingyun Xu, Mingxu Zhang, Jiaming Liu, Yan Shen, Iaroslav Ponomarenko, Jiahui Xu, Liang Heng, Siyuan Huang, Shanghang Zhang, Hao Dong
摘要:在机器人操作任务中,任务目标可以通过多种模态进行传达,例如语言、目标图像和目标视频。然而,自然语言可能存在歧义,而图像或视频可能提供过于详细的规格说明。为解决这些问题,我们提出了一种新颖的方法,利用全面的多模态提示(multi-modal prompts)以简单的方式明确传达低级动作和高级规划。具体而言,对于任务序列中的每个关键帧,我们的方法允许在RGB图像上手动或自动生成简单且具表现力的2D视觉提示(visual prompts)。这些提示表示所需的任务目标,例如末端执行器的姿态以及接触后的期望运动方向。我们设计了一种训练策略,使模型能够解析这些视觉-语言提示,并在SE(3)空间中预测相应的接触姿态和运动方向。此外,通过顺序执行所有关键帧步骤,该模型能够完成长时间跨度的任务。这一方法不仅有助于模型清晰理解任务目标,还通过提供易于解释的提示,增强了模型在未见任务中的稳健性。我们在仿真和真实环境中对该方法进行了评估,实验结果表明其具备强大的操作能力。
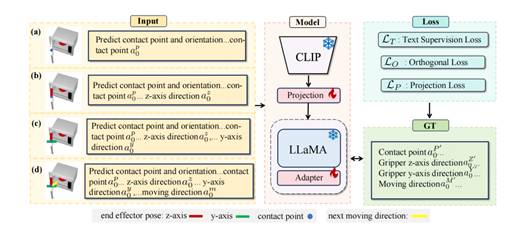
图6 We design training pairs that convey varying levels of information to enable the model to comprehend each type of prompt and introduce loss functions to guide it in predicting accurate poses.